local variable, global variable
변수는 함수내에서 선언이 되면 해당 함수가 호출 시에 생성이 되고 함수가 종료되면 소멸된다. 이러한 변수를 지역변수라고 한다. 함수 밖에서 선언이 된 변수는 전역변수라고 부르며 프로그램이 실행되면 생성이 되며 프로그램이 종료되어야 소멸한다.
var a = 10 //전역변수 -> 함수 내외에서 호출 가능
var b = 20 //전역변수
func fn_1(){
var c = 3000 //지역변수 -> 해당함수 내에서만 호출 가능, 함수 종료시 소멸.
print("\t fn_1()시작 a:\(a), b:\(b), c:\(c)")
a = 11 //전역변수 a 변경
b = 21 //전역변수 a 변경
print("\t fn_1()끝 a:\(a), b:\(b), c:\(c)")
}
func fn_2(){
var d = 4000 //지역변수 -> 해당함수 내에서만 호출 가능, 함수 종료시 소멸.
print("\t fn_2()시작 a:\(a), b:\(b), d:\(d)") //전역변수 b호출
a=13 //전역변수 a 변경
var b = 23 //지역변수 b 선언 -> 우선순위가 전역변수보다 높다.
print("\t fn_2()끝 a:\(a), b:\(b), d:\(d)") //지역변수 b 호출
}
func fnTot(){
var e = 5432
print("fnTot()시작 a:\(a), b:\(b), e:\(e)")
fn_1() //fn_1() 함수를 호출했다 하더라도, fn_1()의 지역변수를 호출할수는 없다.
print("fnTot()중간 a:\(a), b:\(b), e:\(e)")
a=12 //전역변수 a 변경
fn_2() //fn_2() 함수를 호출했다 하더라도, fn_2()의 지역변수를 호출할수는 없다.
print("fnTot()끝 a:\(a), b:\(b), e:\(e)")
}
fnTot()
지역변수의 특징은 선언된 함수 내에서만 접근이 가능하다는 점이다. 다른 함수가 호출하였다 하더라도 해당 지역변수에는 접근할 수 없으며, 반대로 전역변수의 경우 어디서든 접근이 가능한 것이 특징이다.
selfCall
selfCall(재귀함수)는 자기 자신을 호출하는 함수를 뜻한다. 반복문과 마찬가지로 탈출조건을 적지 않으면 무한루프에 빠지게 되니 주의깊게 작성해야 한다.
//재귀함수를 이용하여 0부터 매개변수까지의 합 구하기
var pre = ""
func fn(no:Int) -> Int{
let myPre = pre
pre += "\t"
var res = no
print("\(myPre)fn() 시작:\(no), \(res)")
if no > 0 { //조건
// let rr = fn(no:no-1) //증감 : -1
// res += rr
// print(no, rr, res)
res += fn(no:no-1)
}
print("\(myPre)fn() 끝:\(no), \(res)")
return res
}
var qq = fn(no:3) //초기값
print("main: \(qq)")
pre변수는 함수의 출력부분을 편하게 구분하기 위해 출력한 것이므로 주의깊게 보지 않아도 된다. fn(3)의 호출 흐름을 간단하게 그려보았다.

class
클래스는 표현하고자 하는 것을 자료형으로 정의한 것이라고 생각하면 된다.
표현하고자 하는 것의 속성 및 상태를 변수로 표현하고, 그것의 동작을 함수로 표현한다. 이때 클래스에 정의한 변수를 멤버변수, 클래스에 정의한 함수를 메소드라고 지칭한다. 클래스를 정의하고 사용하기까지 4단계를 거친다.
- 클래스 정의
- 클래스 형의 변수의 선언
- 생성잘르 통해 생성 (heap영역에 생성)
- 인스턴스 클래스의 호출
클래스 정의
클래스를 정의한다. 멤버변수를 통해 표현하고자 하는 것의 속성과 특징을 서술하고, 메소드를 통해 동작을 표현한다.
class AAA {
var aa = 10 //멤버변수: 상태
var tt = "아기상어" //멤버변수
func fn_1(){ //메소드: 동작
print("\(aa), \(tt) AAA fn_1() 실행") //해당 클래스의 멤버요소 접근 가능
}
func fn_2(){ //메소드
print("AAA fn_2() 실행")
}
}클래스형 변수 선언
클래스를 실체화하여 사용하기 위해 변수로 선언한다.
var a1:AAA //정의된 클래스를 통해 변수를 선언한다.
var a2:AAA //물론 여러개를 만들 수 있다.생성
선언한 변수를 사용하기 위해 생성자로 초기화한다.
a1=AAA() //생성 및 대입
a2=AAA()인스턴트 클래스 호출 및 접근
변수를 통해 메소드 호출 및 멤버변수에 접근 한다.
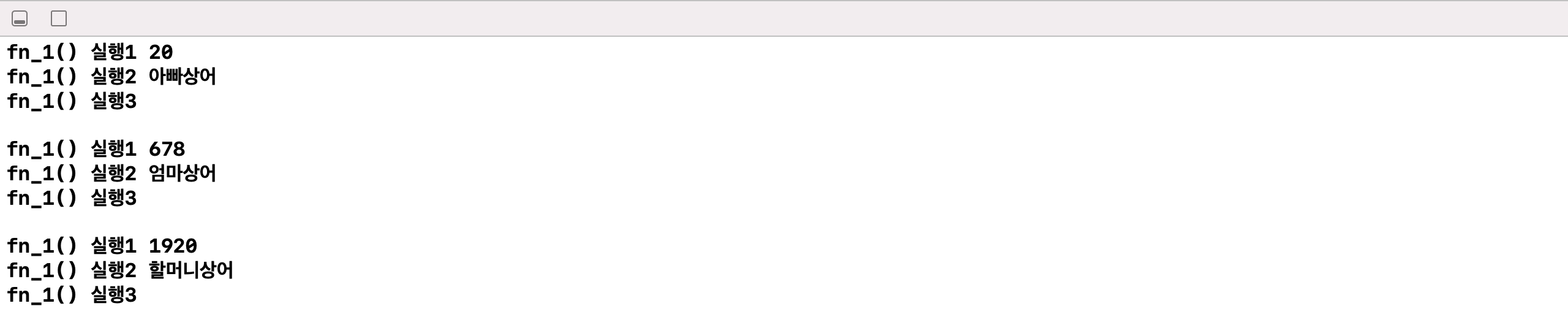
print(a1) //인스턴스 변수 호출 ::> 클래스 타입을 알 수 있다.
print(a1.aa,a1.tt) //멤버변수 호출
print(a2.aa,a2.tt) //멤버변수 호출
a1.fn_1() //메소드 호출
a2.fn_1() //메소드 호출
a1.aa = 123 //멤버변수에 값 대입
a1.tt = "아빠상어" //멤버변수에 값 대입
print("a1.aa:",a1.aa,"/ a1.tt:",a1.tt) //멤버변수 호출
print("a2.aa:",a2.aa,"/ a2.tt:",a2.tt) //멤버변수 호출
print("-----------------")
a1.fn_1() //메소드 호출
a1.fn_2() //메소드 호출
a2.fn_1()
a2.fn_2()
실행 결과를 보면 멤버변수는 각 독립된 존재인 것을 알 수 있다.
클래스 예제
클래스를 통해 입력받은 점수로 합계와 평균을 구하는 클래스를 생성해보았다.
class Exam{ //클래스명은 대문자로 시작한다.
var name = ""
var score = [Int]()
var tot = 0, avg = 0
func first(_ nn:String, _ jj:Int...){
//1.입력부
self.name = nn
self.score = jj
//2.계산부
self.calc()
//3.출력부
self.ppp()
}
func calc(){
tot = 0
for i in score{
tot += i
}
avg = tot / score.count
}
func ppp(){
print("\(name)\t\(score)\t총점:\(tot)\t평균:\(avg)")
}
}비중있게 보아야 할 부분이라면 first()함수에서 매개변수의 값을 멤버변수에 옮겨 담은 후, calc()함수와 ppp()함수를 호출하여 한번에 입력, 계산, 출력을 동작하게 하는 부분이다. 코드가 짧다면 굳이 함수를 나눌 필요없이 first()함수 안에 다른 코드들을 적으면 되지만, 함수의 내용이 커지면 예제와 같이 분리하여 작성하는 것이 분업, 코드의 유지보수에도 더 편리하다.
var st1 = Exam() //Exam()형태의 변수 생성
var st2 = Exam()
st1.first("한가인", 77,78,71) //입력과 동시에 출력.
st2.first("두가인", 87,88,81)
'iOS > TJ' 카테고리의 다른 글
| day13_initializer, self, inheritance (0) | 2021.07.01 |
|---|---|
| day11_param, return, funcCall (0) | 2021.06.18 |
| day10_func() (0) | 2021.06.17 |
| day09_dictionary, set (0) | 2021.06.16 |
| day08_multiArray, tuple (0) | 2021.06.03 |