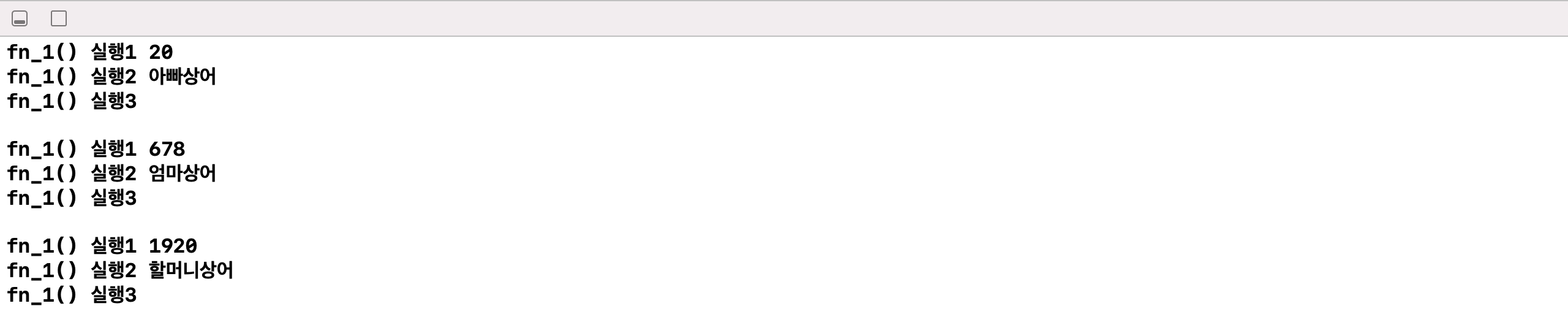
fn_1()함수에 매개변수를 보면 bnbn bb : String이라 되어있다. 스위프트의 함수가 다른언어들과의 차이점이 매개변수와 인수를 따로 구분한다는 점이다. bnbn은 인수, 즉 외부에서 호출 시의 매개변수를 부르는 이름이다. 반대로 함수 내부에서는 bnbn이 아닌 bb로 사용해야 매개변수로서 접근이 가능하다. 코딩시 영어문장처럼 흘러가도록 하기위해 이와 같이 매개변수와 인수를 따로 구분하는 것으로 알고있다. 해당 문법이 불편하면 매개변수만 적게되으면 된다. 인수와 매개변수를 통일하여 사용 할 수 있다.
func minGo(arr:[Int]) -> Int{
var res = arr[0] //매개변수로 배열의 첫번째 요소를 res변수에 담는다.
for i in arr{
if res > i {
res = i //res의 값보다 더 작은 값의 요소를 찾으면 res에 대입한다.
}
}
return res //res값을 반환한다.
}
var res = minGo(arr: [34,56,7,12,4,98,23,167,11])
print("res:",res)
//선언 및 생성
var dic:Dictionary<String:String> = ["red":"빨강","blue":"파랑","green":"파랑","yellow":"노랑"]
//키는 중첩되면 안된다.
print(dic) //딕셔너리는 순서가 랜덤하게 출력된다.
딕셔너리의 출력 결과를 보면 순서없이 출력되는 모습을 볼 수 있다.
선언 및 초기화
선언 및 초기화에는 여러가지 방법들이 있다.
//선언 및 비어있는 형태로 생성
var dic2:[String:Int] = [:] //String형태의 키, Int형태의 값으로 생성.
print(dic2)
var dic3:Dictionary<Int,Int> = [:] //Int형태의 키, Int형태의 값으로 생성.
print(dic3)
dic3 = [3:100,7:200,10:5] //키-값 대입하여 초기화
print(dic3)
var dic4 = [String:String]() //비어있는 형태로 생성
print(dic4)
var dic5 = Dictionary<Int,String>() //비어있는 형태로 생성
print(dic5)
원소 호출
딕셔너리의 원소(값)의 호출방법이다. 키를 이용하여 호출 및 접근한다.
//원소호출
//print(dic[0]) 딕셔너리는 순서가 없다.
print("dic[\"red\"]:",dic["red"]!) //옵셔널로 반환된다. 값이 없을수도 있기에
print("dic[\"pink\"]:",dic["pink"]) //없는 키를 출력시 nil이 출력된다.(옵셔널)
기본적으로 출력 형태는 옵셔널로 출력된다. 키와 값의 존재유무가 확실하지 않기 때문이다.
추가 및 대입
딕셔너리는 튜플과 달리 원소의 추가가 가능하며, 기존의 키에 해당하는 값의 변경 또한 가능하다.
//대입 및 추가
dic["yellow"] = "누렁이" //기존의 키에 새로운 값 대입
dic["orange"] = "주황" //'키-값'의 추가도 가능하다.
print(dic)
삭제
대입 및 추가와 같이 키를 사용하여 값을 삭제할 수 있다.
//삭제
print(dic) //기존 배열 출력
dic.removeValue(forKey: "green") //green 키-값 삭제
print(dic) //삭제된 배열 출력
출력
딕셔너리또한 반복문과 사용하면 편리하게 출력 및 제어할 수 있다.
//개별 출력
for i in dic {
print(i) //튜플형태로 출력된다.
print(i.key, i.value) //키와 값을 따로 출력할 수 있다.
}
print("------------\n")
for (k, v) in dic{
print(k,v) //키와 값을 더 간략하게 출력할 수 있는 방법이다.
}
var k = dic.keys //키만 따로 뽑아낼 수 있다.
print(k) //배열형태로 출력된다.
var v = dic.values //값만 따로 뽑아낼 수 있다.
print(v) //배열형태로 출력된다.
메소드
딕셔너리의 여러가지 메소드를 통해 데이터를 반환받을 수 있다.
//비어있는 딕셔너리인지 확인
print(dic.isEmpty)
//딕셔너리의 갯수 출력
print(dic.count)
//딕셔너리 비우기
dic.removeAll()
print(dic.isEmpty)
print(dic.count)
Dictionary 예제
중복된 숫자의 배열을 받아서 각 숫자가 몇번 중복되었는지 딕셔너리형태로 출력해보자.
let hit = [3,4,7,8,1,3,5,7,1,3,4,8,1,1] //안타 친 등번호 순서
var hitData = [Int:Int]() //비어있는 딕셔너리 생성
for i in hit{
var no = 1
// print(i, hitData[i]==nil) //해당 데이터가 중복인지 확인.
if hitData[i] != nil{ //중복된 자료라면,
no += hitData[i]! //hitData[i]의 값을 1증가한다.
}
hitData[i] = no //중복이 되지 않으면서 대입이 된다.
}
print(hit) //기존 데이터 출력
print(hitData) //[등번호 : 안타횟수] 형태로 출력
[번호 : 중복횟수] 형태로 출력이 되지만, 딕셔너리는 순서없는 자료형이기에, 랜덤하게 출력이 된다. 오름차순으로 정렬하려면 따로 가공하여 출력해야한다.
//dictionary는 순서없는 자료형이기에, sort()함수는 불가능. sorted()함수를 이용하여 정렬된 자료를 반환받아 처리해야한다.
for k in hitData.keys.sorted(){
print("\(k):\(hitData[k]!)개","",separator: "\t",terminator: "") //등번호, 안타횟수 출력
}
최종출력은 다음과 같다. print()함수의 separactor 속성은 다음 데이터 출력 시 기존 데이터와 구분하기 위해 출력내용을 정해주는 속성이다. 한번에 데이터가 두개 이상 출력이 되어야 적용되므로 기존 자료와 공백 데이터("")를 출력하게 작성했다.
Set
딕셔너리는 키와 값으로 이루어진 순서없는 데이터의 모음(컬렉션 타입)이다. 하지만 키-값 쌍의 형태가 아닌 단일형태의 순서없는 데이터 모음이 필요한 경우 Set을 사용한다. 즉 키로만 이루어진 딕셔너리라고 생각하면 된다.
var변수이름 : Set<자료형> = [자료,자료,자료]
var arr = [11,22,11,33,22,44,11,55] //배열 중복데이터가 허용된다. 순서가 있다.
var ss1:Set<Int> = [11,22,11,33,22,44,11,55] //set 중복데이터는 생략되어 저장된다. 순서가 없다.
print(arr)
print(ss1)
값으로 이루어진 딕셔너리가 아닌 키로만 이루어진 모임이라고 설명한 것은 바로 데이터의 중복이 허용되지 않는다는 점 때문이다. 일반적인 배열과 큰 차이이다. 출력 모습도 배열은 인덱스 순서로 출력되는 반면, set은 순서없이 출력이 되는 모습을 볼 수 있다.
선언 및 초기화
var ss2 = Set<String>() //빈 set생성
var ss3:Set<Int> = [] //빈 set생성
print(ss2)
print(ss3)
ss2 = ["a","b","d"] //빈 set 초기화
ss3 = [3,4,4,5,6,7] //빈 set 초기화
print(ss2)
print(ss3)
요소 갯수 출력
var ss1:Set<Int> = [11,22,11,33,22,44,11,55]
//set 요소 갯수출력
print(ss1.count)
중복이 허용되지 않아 ss1의 요소는 5개로 출력한다.
반복문 출력
var ss1:Set<Int> = [11,22,11,33,22,44,11,55]
//반복문 출력
for i in ss1 {
print(i) //원소를 하나씩 가지고 올 수 없다. 순서가 없기 때문이다.
}
Set은 배열과 달리 인덱스가 없기에 반복문을 통해 요소를 하나씩 출력할 수 없다.
요소 검색, 추가, 삭제
var ss1:Set<Int> = [11,22,11,33,22,44,11,55]
//요소 검색
print(ss1.contains(33)) //요소 33이 있는가?
print(ss1.contains(100))//요소 100이 있는가?
//요소 추가
ss1.insert(77) //요소 77 추가 *중복데이터를 추가하면 변화가 일어나지 않는다.
print(ss1)
//요소 삭제
ss1.remove(22) //요소 22 삭제
print(ss1)
isEmpty, 전체삭제
var ss1:Set<Int> = [11,22,11,33,22,44,11,55]
//빈 set인지 확인
print(ss1.isEmpty) //bool return
//요소 전체삭제
ss1.removeAll() //요소 전체삭제
print(ss1.isEmpty)
var lotto1 = [Int]()
var lotto2 = Set<Int>()
while true {
let no = Int.random(in: 1...45) //1부터 45까지 랜덤번호 생성 메소드
lotto1.append(no) //배열에 요소 추가
lotto2.insert(no) //set에 요소 추가
if lotto2.count == 7 { //set의 요소가 7개가 되면 종료
break
}
}
print("lotto1: \(lotto1)") //배열의 경우 겹치는 수가 존재한다.
print("lotto2: \(lotto2)") //set의 경우 겹치는 수가 없다.
배열과의 비교를 통해 두개를 작성했다. 배열의 경우 중복이 허용되기 때문에 중복된 숫자가 생성된다. 하지만 set의 경우 중복을 허용하지 않기에 요소가 7개가 될 때 반복문을 탈출하면 된다.
set 예제2
set을 이용하여 빙고판을 만들어 보자.
var number = Set<Int>()
var cnt = 0
while number.count < 25{ //set의 요소가 25가 될때까지 랜덤숫자 삽입
number.insert(Int.random(in: 1...100))
}
for i in number{
cnt += 1
print(i,terminator: "\t") //줄 변경 없이 출력
if cnt % 5 == 0 { //cnt가 5의 배수가 되면 줄 변경
print()
}
}
set의 중복 불허용의 특성을 이용하여 5x5 숫자빙고를 출력하였다.
set 예제3
각 리스트의 중복을 제거하는 예제이다.
let first:Set<String> = ["박재상","박정권", "최정", "김광현", "엄정욱", "박희수", "이호준"]
let second:Set<String> = ["이호준", "엄정욱", "박재홍", "이신협", "장동건"]
let fa:Set<String> = ["이병규", "이승엽", "박정권", "장동건", "박용택", "홍성흔"]
print("변경 전---------------------------")
print("1군 리스트:",first)
print("2군 리스트:",second)
print("FA 리스트:",fa)
let afterFirst = first.subtracting(second).subtracting(fa) //1군 - 2군 - FA
let afterSecond = second.subtracting(fa) //2군 - FA
let afterFa = fa.subtracting(first).subtracting(second) //FA - 1군 - 2군
print("변경 후---------------------------")
print("1군 리스트:",afterFirst)
print("2군 리스트:",afterSecond)
print("FA가능 리스트:",afterFa)
var st1 = [56,57,59] // -> 자료형: [Int]
var st2 = [86,87,89]
var st3 = [76,77,79]
var st4 = [96,97,99]
print(st1)
print(st2)
print(st3)
print(st4)
var studs:[[Int]] = [st1,st2,st3,st4] //[Int]의 배열형태. 즉, 배열들의 배열 -> 2차원배열
print(studs)
var score = [[77,79,71],[57,59,51,50],[97,99],st4,studs[0]] // [[Int]]형 2차원 배열
print(score) //2차원 배열 출력
for i in score{
print(i) //2차원 배열의 요소에 접근. 즉 2차원 배열안의 배열들을 출력한다.
for k in i {
print(k) //2차원 배열의 배열 속 요소 출력.
}
}
print("score.count:",score.count) //2차원 배열의 요소갯수 -> 2차원 배열 속 '배열의 갯수'
print("score[0]:",score[0],score[0].count) //2차원 배열의 0번째 배열접근, 0번째 배열의 원소갯수
print("score[1]:",score[1],score[1].count) //2차원 배열의 1번째 배열접근, 1번째 배열의 원소갯수
print("score[2]:",score[2],score[2].count) //2차원 배열의 2번째 배열접근, 2번째 배열의 원소갯수
print("score[3]:",score[3],score[3].count) //2차원 배열의 3번째 배열접근, 3번째 배열의 원소갯수
print("score[4]:",score[4],score[4].count) //2차원 배열의 4번째 배열접근, 4번째 배열의 원소갯수
2차원 배열도 배열에 관련된 함수를 사용할 수 있다. 접근을 몇 번하느냐에 따라 결과가 달라지는 모습을 볼 수 있다.
print("score[4]:",score[4],score[4].count) //4번째 배열접근, 4번째 배열의 원소갯수
print(score[4][0],score[4][1],score[4][2],separator: " ") //2차원 배열 속 4번째 배열의 요소 출력
2차원 배열에 접근하게 되면 배열에 접근이 가능하고, 한번 더 접근하면 그 안의 요소에 접근이 가능하다.
2차원 배열 예제
2차원 배열을 이용한 예제다. 2차원 배열의 각 배열의 합, 평균, 원소의 평균을 구해보자.
var score = [[10,20,30], [300,400,500,600], [1,3,5,7,9]]
var total = 0
var cnt = 0
for i in score {
var sum = 0
for k in i{ //2차원 배열속 배열을 순회한다.
sum += k //각 배열속의 원소들의 합계를 구한다.
}
print(i, "합계:\(sum)", "평균:\(sum/i.count)")
//2차원 배열속 배열들 출력, 배열속 원소들의 합계, 배열속 원소들의 평균 출력
total += sum //합계들의 총합 계산(2차원배열의 총합)
cnt += i.count //원소들의 갯수 총합(2차원배열의 전체 평균을 얻기위함)
}
print(score, "배열합계:\(total)", "배열평균:\(total/score.count)", "원소평균:\(total/cnt)", "원소갯수:\(cnt)개")
Tuple
배열의 특징은 같은 자료형만 묶을 수 있다는 점이다. 이러한 점이 경우 따라서 편리하기도 하지만 반대로 다른 자료형과 함께 다룰 때에는 불편하게 작용한다. 이때 사용하는 것이 튜플이다. 튜플은 여러 자료형을 함께 묶을 수 있다.
var tt3:(name:String, height:Int, marriage:Bool) = ("현빈",188,false) //각 요소에 이름을 지정할 수 있다.
print(tt3)
print(tt3.name, tt3.0) //각 요소에 이름으로 접근이 가능하다.
print(tt3.height, tt3.1)
print(tt3.marriage, tt3.2)
튜플 활용
튜플의 데이터를 다른 변수에 한번에 대입하는 작업도 가능하다.
var t2:(String,Int,Double) = ("젤리빈", 120, 987.432)
var nn:String
var hh:Int
var dd:Double
(nn,hh,dd) = t2 //튜플의 자료형에 맞게 여러 변수에 한번에 대입이 가능하다.
print(nn)
print(hh)
print(dd)
typealias
typealias를 사용하여 자료형을 미리 묶어놓고 사용할 수 있다.
typealias mem = (name:String, height:Int, marriage:Bool) //여러 자료형을 mem이라는 자료형으로 묶었다.
var tt4:mem = ("김우빈", 183, true) //mem 자료형으로 튜플을 생성한다.
var tt5:mem = ("커피빈", 163, false) //mem 자료형으로 튜플을 생성한다.
var tt6:mem = ("미스터빈", 186, true) //mem 자료형으로 튜플을 생성한다.
print(tt4)
print(tt5)
print(tt6)
var tts:[mem] = [tt4,tt5,tt6] //typealias로 생성한 자료형으로 배열을 만들 수 있다.
print(tts)
튜플 예제
튜플을 이용한 예제이다. 배열속 튜플의 sum과 avg를 계산하여 대입하고, 등급을 계산 후 출력해보자.
typealias stud = (name:String, score:[Int], sum:Int, avg:Int, grade:String)
var exam:[stud] = [
("이효리",[77,78,71],0,0,""),
("삼효리",[57,58,51],0,0,""),
("사효리",[97,98,91],0,0,""),
("오효리",[67,68,61],0,0,""),
("육효리",[87,88,81],0,0,"")
]
//연산부
for i in 0..<exam.count{
for k in exam[i].score{
exam[i].sum += k //i번째 튜플의 합 계산
}
exam[i].avg = exam[i].sum / exam[i].score.count //i번째 튜플의 평균 계산.
if exam[i].avg >= 90 {
exam[i].grade = "수"
} else if exam[i].avg >= 80{
exam[i].grade = "우"
} else if exam[i].avg >= 70{
exam[i].grade = "미"
} else if exam[i].avg >= 60{
exam[i].grade = "양"
} else if exam[i].avg >= 50{
exam[i].grade = "가"
} else{
exam[i].grade = "미달"
}
}
//출력부
for st in exam{
print(st)
}
주목해야할 점은 등급을 계산하는 부부이다. 조건문을 이용하여 계산하는 것이 대부분이다. 하지만 미세한 차이지만 더 빠르고 훨씬 짧은 코드로 계산이 가능하다.
typealias stud = (name:String, score:[Int], sum:Int, avg:Int, grade:String)
var exam:[stud] = [
("이효리",[77,78,71],0,0,""),
("삼효리",[57,58,51],0,0,""),
("사효리",[97,98,91],0,0,""),
("오효리",[67,68,61],0,0,""),
("육효리",[87,88,81],0,0,"")
]
//연산부
for i in 0..<exam.count{
for k in exam[i].score{
exam[i].sum += k //i번째 튜플의 합 계산
}
exam[i].avg = exam[i].sum / exam[i].score.count //i번째 튜플의 평균 계산.
let grade = ["미달","미달","미달","미달","미달","가","양","미","우","수"]
exam[i].grade = grade[exam[i].avg / 10]
}
//출력부
for st in exam{
print(st)
}
평균을 10으로 나눈 결과로 인덱스를 정하고, 배열에 저장해둔 등급 결과는 정해둔 인덱스를 이용하여 출력하면 된다.
코드는 더 짧아지고 컴퓨터는 기존의 조건문의 연산보다 더 적은 연산을 통해 결과를 출력할 수 있다.
배열(Array)이란, 같은 자료형들의 묶음 이라고 생각하면 된다. 같은 자료형의 여러 데이터를 순서대로 저장하는 변수이다.
var배열이름 : [자료형] = [값1, 값2, 값3, 값4, ... ]
var배열이름 : Array<자료형> = [값1, 값2, 값3, 값4, ... ]
var arr : [Int] = [20,10,40,70,10] //배열변수 선언 및 초기화. 배열의 원소는 중복되어도 된다.
print("arr: \(arr)") //배열 호출
print("arr[0]: \(arr[0])") //배열원소 호출 ::> 배열변수[인덱스번호]
print("arr[1]: \(arr[1])") //배열원소 호출 ::> 배열변수[인덱스번호]
print("arr[2]: \(arr[2])") //배열원소 호출 ::> 배열변수[인덱스번호]
print("arr[3]: \(arr[3])") //배열원소 호출 ::> 배열변수[인덱스번호]
//print("arr[5]: \(arr[5])") //없는 원소는 호출 시 에러가 발생한다.
배열의 원소를 호출할 시 배열이름[인덱스번호] 형식을 통해 접근할 수 있다. 배열의 인덱스 번호는 0번부터 시작한다.
빈 배열 선언 및 초기화
//비어있는 배열 생성
var arr1:[Int] //초기화하지 않음. 호출불가
var arr2:[Int] = [] //비어있는 배열로 선언 및 초기화
var arr3:[Int] = [Int]() //비어있는 배열로 선언 및 초기화.
var arr4:[Int] = Array<Int>() //비어있는 배열로 선언 및 초기화.
var arr5:Array<Int> = [Int]() //비어있는 배열로 선언 및 초기화.
var arr6:Array<Int> = Array<Int>() //비어있는 배열로 선언 및 초기화.
print("arr2:",arr2)
print("arr3:",arr3)
print("arr4:",arr4)
print("arr5:",arr5)
print("arr6:",arr6)
비어있는 배열을 넣는 방법은 여러가지가 있다. 좌항이나 우항에 한곳이라도 자료형이 명시되어있다면 한 쪽은 자료형 생략도 가능한 점을 알아두자. 변수와 마찬가지로 초기화하지 않은 배열은 호출이 불가능하다.
for문과의 조합
var arr_A = ["호랑이","표범","고양이","재규어","치타","퓨마"]
for i in arr_A{
print(i)
}
예시와 같이 배열은 for문에서 사용할 경우 편리하게 사용 가능하다. for문의 임시상수 i는 열거형 데이터의 순번을 돌며 원소들을 하나씩 복사해온다는 장점이 있다.
var arr10 = [12,54,67,34,23,98,57,36]
var sum = 0
for i in arr10 {
sum += i
print("\(i): \(sum)")
}
print(sum)
-> 배열형태의 여러 요소를 해당 인덱스에 한번에 추가한다. 해당 인덱스에 있던 기존 요소는 다음으로 밀려난다.
var arr = [10,20,30]
print("arr: \(arr)")
arr.append(400) //배열의 마지막 원소 뒤에 요소 400 추가
print("arr.append(400)")
print("arr: \(arr)")
arr.insert(35, at: 1) //배열의 1번 인덱스 위치에 요소 35 추가
print("arr.insert(35, at: 1)")
print("arr: \(arr)")
arr.insert(contentsOf: [56,33,100], at: 1) //배열의 1번 인덱스에 여러 요소 한번에 추가
print("arr.insert(contentsOf: [56,33,100], at: 1)")
print("arr: \(arr)")
요소삭제
배열 속 요소를 삭제하는 여러가지 함수가 있다.
remove(at:인덱스)
-> 해당 인덱스의 요소를 삭제한다. 삭제할 요소를 리턴해준다.
removeFirst()
-> 배열의 가장 첫번째 요소를 삭제한다. 삭제할 요소를 리턴해준다.
removeLast()
-> 배열의 가장 마지막 요소를 삭제한다. 삭제할 요소를 리턴해준다.
popLast()
-> 배열의 가장 마지막 요소를 삭제한다. 삭제할 요소를 리턴해준다.(옵셔널)
removeSubrange(범위)
-> 범위에 해당하는 인덱스의 요소를 삭제한다. 리턴요소가 없다.
dropFirst()
-> 첫번째 요소를 제외하고 모든 요소을 리턴한다. 본배열에는 변경이 일어나지 않는다.
dropLast()
-> 마지막 요소를 제외하고 모든 요소를 리턴한다. 본배열에는 변경이 일어나지 않는다.
var arr = [10,20,30,40,50,60,70]
print("arr: \(arr)")
var no = arr.remove(at: 2) //2번 인덱스 요소 삭제, 삭제할 요소를 반환해준다.
print("arr.remove(): \(arr)") //본배열에 2번인덱스요소가 삭제된다.
print("arr.remove() return: \(no)") //삭제된 요소는 반환되어 no변수에 복사된다.
no = arr.removeFirst() //가장 첫번째 요소 삭제, 삭제할 요소를 반환해준다.
print("arr.removerFirst(): \(arr)")
print("arr.removerFirst() return: \(no)")
no = arr.removeLast() //가장 마지막 요소 삭제, 삭제할 요소를 반환해준다.
print("arr.removerLast(): \(arr)")
print("arr.removerLast() return: \(no)")
no = arr.popLast()! //마지막 요소 삭제, 삭제요소 반환. popFirst()는 없다.
print("arr.popLast(): \(arr)")
print("arr.popLast() return: \(no)")
arr = [10,20,30,40,50,60,70]
print("arr:\(arr)")
var sub = arr.removeSubrange(2...4) //범위삭제. 리턴요소가 없다. 2번, 3번, 4번 인덱스의 요소 삭제.
print("arr.removeSubrange(2...4): \(arr)")
print("arr.removeSubrange(2...4) return: \(sub)")
var arr2 = arr.dropFirst() //본 배열에는 변경없음. 첫번째 요소를 제외하고 리턴을 준다.
print("arr: \(arr)")
print("arr.dropFirst() : \(arr2)")
arr2 = arr.dropLast() //본 배열에는 변경없음. 마지막 요소를 제외하고 리턴을 준다.
print("arr: \(arr)")
print("arr.dropLast() : \(arr2)")
인덱스
index(of:요소)
-> 요소가 위치한 인덱스를 반환한다. 여러개가 있을경우, 그중 가장 첫번째 요소의 인덱스를 반환 (옵셔널)
firstIndex(of:요소). *index(of: )와 같은 함수. 더 이상 index(of:)는 사용하지 않는다.
-> 요소가 위치한 인덱스를 반환한다. 여러개가 있을경우, 그중 가장 첫번째 요소의 인덱스를 반환 (옵셔널)
lastIndex(of:요소)
-> 요소가 위치한 인덱스를 반환한다. 여러개가 있을경우, 그중 가장 마지막 요소의 인덱스를 반환 (옵셔널)
arr = [11,44,22,33,44,66,88,33,44,88,66,44,22]
print("arr: \(arr)")
print("arr.index(of: 44)!:",arr.index(of: 44)!) //해당 요소가 어느 인덱스에 위치하는지 찾아준다. (옵셔널)
print("arr.index(of: 88)!:",arr.index(of: 88)!) //해당 요소가 어느 인덱스에 위치하는지 찾아준다.
print("arr.index(of: 100):",arr.index(of: 100)) //해당 요소가 어느 인덱스에 위치하는지 찾아준다.
//옵셔널이기에 요소가 없다면 nil이 반환된다.
print("arr.firstIndex(of: 44)!:",arr.firstIndex(of: 44)!) //해당 요소 중 첫번째 인덱스를 찾아준다. (옵셔널)
print("arr.lastIndex(of: 44)!:",arr.lastIndex(of: 44)!) //해당 요소 중 마지막 인덱스를 찾아준다. (옵셔널)
그렇다면 배열의 중간에 위치한 44의 인덱스를 알고싶은 경우는 어떻게 해야할까?
arr = [11,44,22,33,44,66,88,33,44,88,66,44,22]
arr2 = arr[2...8]
print(arr2)
print(arr2.index(of:44)!) //-> 배열을 옮겨 담아도 기존에 있었던 인덱스 번호를 그대로 가지고 온다.
//그렇다면 나는 중간에 위치한 44의 인덱스를 찾고싶다.
print("arr의 중간 인덱스:",arr[(arr.firstIndex(of: 44)!+1) ..< (arr.lastIndex(of: 44)!)].firstIndex(of: 44)!)
배열의 범위를 제한하여 찾을 수 있다. 즉 첫 번째 44의 인덱스 이후 ~ 마지막 44의 인덱스 이전 이라는 범위에서 44의 첫 번째 인덱스를 검색하면 중간에 위치한 인덱스를 찾게된다.
요소
contains(요소)
-> 요소가 존재하는지 bool형태를 반환하여 알려준다.
replaceSubrange(범위, with=[ 요소1, 요소2, 요소3, ... ])
-> 범위에 해당하는 인덱스의 명시한 요소들로 바꾼다.
count
-> 요소의 갯수를 반환해준다.
arr = [11,22,33,44,55,66,77,88,99]
print("arr:",arr)
print(arr.contains(44)) //요소 중 44가 존재하는지 알려준다.
print(arr.contains(100)) //요소 중 100이 존재하는지 알려준다.
arr.replaceSubrange(2..<4, with: [100,200,300]) //2,3번째 요소를 [100,200,300]으로 교체
print("after \"arr.replaceSubrange(2..<4, with: [100,200,300]\" : \(arr)")
print("arr:",arr)
print("arr.count:",arr.count) //원소갯수 출력
정렬
reverse()
-> 현재 배열을 역순으로 정렬한다. 리턴값은 없다.
reversed()
-> 현재 배열의 역순을 리턴한다. 본 배열은 바뀌지 않는다.
var arr = [11,33,55,44,22,66,77,88,99] //기존 배열 생성
print("arr:\(arr)\n") //기존 배열 출력
var arr2 = arr.reversed() //반전된 값을 arr2로 리턴
print(arr2) //arr2 출력
print("arr.reversed():",terminator: "") //줄바꿈 없이 출력
for i in arr2{
print(i,"",separator: " ",terminator: "") //줄바꿈 없이 출력
}
print("\n")
print("arr:\(arr)") //기존배열 출력. 변화가 없다는 것을 확인.
arr.reverse() //기존 배열을 반전.
print("arr.reverse():\(arr)") //기존 배열 출력
sort()
-> 현재 배열을 오름차순으로 정렬한다. 리턴값은 없다. (by:<)가 기본값으로 생략되어있다.
var txtArr = ["현빈","김우빈","원빈","투빈","장희빈","미스터빈"]
print(txtArr)
txtArr.sort() //문자열 배열도 정렬이 가능하다.
print("text.sort():",txtArr)
sorted()
-> 현재 배열을 오름차순으로 정렬하여 리턴한다. 본 배열에는 변화가 없다. (by:<)가 기본값으로 생략되어있다.
sorted(by:<)
-> 현재 배열을 오름차순으로 정렬하여 리턴한다. 본 배열에는 변화가 없다.
sorted(by:>)
-> 현재 배열을 내림차순으로 정렬하여 리턴한다. 본 배열에는 변화가 없다.
print(arr) //기존 배열 출력
print(arr.sorted(by:<)) //sorted(by:<)함수 리턴 출력
print(arr.sorted(by:>)) //sorted(by:>)함수 리턴 출력
print(arr.sorted()) ////sorted()함수 리턴 출력
print(arr) //기존배열 출력. 변화가 없다는 것을 확인할 수 있다.
배열은 같은 자료형만 묶을 수 있다. 따라서 복합적인 자료를 다룰 때에는 자료형에 맞는 배열을 여러개 생성하여 다룬다.
var name = ["한가인","두가인","삼가인","사가인","오가인"] //이름이 담기는 배열 생성
var score = [78,56,91,85,64] //점수를 담는 배열을 생성
var glass = [true, false, false, true, true] //안경을 썼는지 여부를 담는 배열 생성
print("0: \(name[0]) \(score[0]) \(glass[0])") //각 배열의 요소를 가져오는 방법.
print("1: \(name[1]) \(score[1]) \(glass[1])")
print("2: \(name[2]) \(score[2]) \(glass[2])")
print("3: \(name[3]) \(score[3]) \(glass[3])")
print("4: \(name[4]) \(score[4]) \(glass[4])")
print("--------------------------------------\n")
for i in 0 ..< name.count{ //count를 사용하여 범위를 정한다.
print("\(i): \(name[i]) \(score[i]) \(glass[i])") //반복문을 사용하여 요소를 가져올 수 있다.
}
반복문이 무한루프에 빠지지 않게 하기 위해 반복문을 제어하는 명령어가 있는데, break와 continue이다.
for i in 10...15{
print("break \(i) 시작-----")
if(i==13){ //13이면 for문 탈출.
break //반복문 탈출 -> 13끝이 출력되지 않고 반복문 종료.
}
print("break \(i) 끝-----")
}
print("break 종료-----")
"break 13 끝"이 출력되지 않은 채 반복문이 종료되었다. 이와 같이 break는 반복문을 종료하는 데에 사용된다.
반복문 제어 - continue
continue 명령문은 반복문의 실행구문을 수행하지않고 다음 반복문으로 넘어가는데에 사용된다.
for i in 10...15{
print("break \(i) 시작-----")
if(i==13){
continue //다음 반복순서로 넘김 -> 13끝이 출력되지 않고 14로 넘어간다.
}
print("break \(i) 끝-----")
}
print("break 종료-----")
break 명령문과 달리, "break 13 끝"의 출력을 건너뛰고 나머지 반복문을 수행하였다.
반복문 - while
조건을 만족하는 동안 실행구문을 반복한다.
while조건{
실행구문
}
var i = 10 //초기값
while i < 20 { //i가 20미만이면 반복수행
print("while 실행 \(i)")
i += 1 //i 1증가
}
주의 해야 할 점은 while문을 사용할 때 에는 조건을 false로 만들어줄 구문이 없다면 무한루프에 빠지게 된다는 점이다.
var i = 0
while true {
print("break start \(i)")
if i == 5 {
break //i가 5가 되면 종료
}
print("break finish \(i)")
i += 1 //i 증가
}
예시와 같이 종료 시점을 정해주는 것을 잊지 말자
readLine()
사용자의 입력을 받는 함수이다. 옵셔널 형태의 String을 반환한다.
print("입력:",terminator: "")
var text = readLine()
print(text)
while문과 readLine()을 통해 간단한 프로그램을 작성해보자. 사용자의 입력을 받고 그 중 짝수만 선택하여 합계와 평균을 구해본다.
var sum = 0 //합계를 저장할 변수 선언
var cnt = 0 //평균 계산을 위한 변수 선언
var avg = 0 //평균 값을 저장할 변수 선언
while true { //반복문 수행
print("입력:",terminator: "")
let input = readLine()! //사용자의 입력을 input변수에 담는다. 옵셔널 형태로 반환하기에 느낌표를 붙여준다.
if input == "x"{ //사용자의 입력이 x라면 반복문 종료.
break
}
let num = Int(input)! //사용자의 입력을 정수형태로 num에 대입
if num % 2 == 0{ //넘어온 사용자의 입력이 짝수인지 확인
cnt += 1 //평균을 구하기 위해 갯수 파악
sum += num //사용자의 입력 합산
avg = sum/cnt //평균 계산
}
print("number:\(num), total:\(sum), avg:\(avg)")
}
print("----------종료되었습니다. 합계:\(sum), 평균:\(avg)----------8")
사용자가 무엇을 입력했는지 보여주기 위해 변수 num은 계속 출력되지만 짝수일 경우에만 sum, avg에 반영되어 출력된다.
for i in stride(from: 50, to: 20, by: -3){ //50부터 20까지 3씩 감소 20미포함
print(i)
}
print("--------------------")
for i in stride(from: 50, through: 20, by: -3){ //50부터 20까지 3씩 감소 20포함
print(i) //i = 12 -> i는 내부 상수이다. 값 변경 불가. + 외부에서 호출 불가
}
for - in 문 이용하여 결과 구하기
중요한 점은 for문의 임시상수 i는 for문 밖에서 호출할 수 없다는 점이다. 따라서 for문에서 이루어지는 계산을 밖으로 가져오고 싶다면 for문 밖에서 선언된 변수를 사용하여 대입해야 한다는 점이다.
var tot = 0
for i in 1...100{
tot += i
print(i,":",tot)
}
print("1부터 100까지의 합계 : \(tot)")
//1부터 100까지 짝수들의 합 구하기
var sum = 0
for i in 1...100{
if i%2 == 0{
sum += i
}
}
print("1부터 100까지의 짝수 합계: \(sum)")
print("--------------------")
sum = 0
for i in stride(from: 0, through: 100, by: 2){ //0부터 100까지 2씩 증가. 100포함
sum += i
}
print("1부터 100까지의 짝수 합계: \(sum)")
이렇게 여러가지 방법으로 같은 결과를 출력할 수 있다.
중첩 for문 - 구구단
for문은 중첩해서 사용이 가능하다. 이렇게 중첩된 반복문의 대표적인 예시가 구구단이다.
print("구구단(1)---------------------------")
for i in 2...9{
print("\(i)단")
for k in 1...9{
print("\(i) * \(k) = \(i*k)")
}
print("\n")
}
임시상수 k가 있는 for문의 입장에서는 i가 외부에서 선언된 상수이다. 즉 k가 있는 for문에서는 임시상수 i를 호출할 수 있다는 얘기이다. 이 점을 이용하여 구구단을 작성할 수 있다.
print("구구단(2)---------------------------")
for i in 2...9{
print("\(i)단", terminator: "\t\t") //1단 2단 3단 ....
}
print()
for k in 1...9{
for i in 2...9{
print("\(i)*\(k)=\(i*k)", terminator: "\t") //2*1=2 3*1=3 4*1=4...
}
print()
}
구구단을 세로로 출력하는 코드이다. 간단하게 i와 k의 위치를 바꾸어 주면 출력이 가능하다. 콘솔은 좌에서 우로 출력한다는 점을 잘 생각하고 코드를 작성하자.
중첩 for문 - 별 그리기
for문의 다음으로 대표적인 예시가 별을 이용하여 도형그리기이다.
print("별그리기(1)---------------------------")
for line in 0...4{ //별을 몇줄을 그을지.
for star in 0...line{ //별을 몇개를 그릴지.
print("*",terminator:"")
}
print("")
}
line이 증가함에 따라 한줄에 *을 그리는 횟수가 증가하여 삼각형이 그려진다.
print("별그리기(2)---------------------------")
for line in 0...4 { //별을 몇줄을 그릴지
for star in line...4{ //별을 몇개를 그릴지
print("*",terminator:"")
}
print("")
}
for line in stride(from: 4, through: 0, by: -1){ //4부터 0까지 1씩 감소. 0포함
for star in stride(from: line, through: 0, by: -1){ //별을 몇개를 그릴지
print("*",terminator:"")
}
print("")
}
이번에는 하나는 범위연산자, 하나는 stride()를 이용하여 역삼각형을 그렸다.
두 코드 마찬가지로 line이 증가 혹은 감소 함에 따라 *을 그리는 횟수가 점점 감소하는 코드이다.
print("별그리기(3)---------------------------")
for line in 0...4 { //별을 몇줄을 그릴지
for star in line...4{ //별을 그리기 전에 공백을 몇개를 그릴지
print(" ",terminator:"")
}
for star in 0...line{ //별을 몇개를 그릴지
print("*",terminator:"")
}
print()
}
for line in 0...4{ //별을 몇줄을 그릴지
for star in stride(from: 4-line, through: 0, by: -1){
//별을 그리기 전에 공백을 몇개를 그릴지
print(" ",terminator: "")
}
for star in 0...line{ //별을 몇개를 그릴지
print("*",terminator:"")
}
print("")
}
앞에 나온 코드를 합치면서 *대신 공백을 출력하면 처음에 그린 삼각형의 반전된 모습을 그릴 수 있다.
var a:Int = 5
if a > 6 {
a = 1000
} else {
a = 2000
}
print("a:",a)
이번엔 else를 통하여 조건식이 거짓일 경우 실행할 구문을 따로 지정하였다. 조건식 a > 6은 거짓이므로 a에 2000이 대입되어 2000이 출력되었다.
if[조건식1] {
[조건1이 참일 때 실행 구문]
}else if [조건식2]{
[조건1이 거짓, 조건2가 참일 때 실행 구문]
} else {
[조건1, 조건2가 모두 거짓일 때 실행 구문]
}
let score = 70
if score >= 80 {
print("우수")
} else if score >= 60 {
print("정상")
} else{
print("미달")
}
이번에는 조건식을 두개를 적었다. if문의 조건을 판단 후 거짓일 경우 else-if 문의 조건을 판단하여 참일 경우, 거짓일 경우 실행 할 구문을 적었다.
let score = 50
if score >= 80 {
print("우수")
} else if score >= 60 {
print("정상")
} else if score >= 40{
print("미흡")
} else {
print("탈락")
}
else-if 문은 원하는 만큼 추가할 수 있다. 단, 선행으로 적은 조건이 거짓일 경우에만 다음 조건으로 넘어가 비교를 하게 되니 순서에 유의하며 작성해야 한다.
조건문 - switch
switch문은 대상이 정해진 값과 같은지 비교하여 구문을 실행하는 조건문이다. defualt는 대상이 비교할 값에 모두 해당 하지 않았을시에 실행되는 구문이다.
switch대상(값) {
case값1:
실행구문
case값2:
실행구문
...
default:
실행구문
}
스위프트의 switch구문은 다른 언어와 많이 다른 모습을 보이는데, 기본적으로 break키워드가 생략되어 따로 적을 필요가 없어진다. case를 연속실행하기 위해서는 fallthrough 키워드를 사용한다.
var score = 70
switch score {
case 80:
print("80입니다.")
case 70:
print("70입니다.")
case 40:
print("40입니다.")
default:
print("기본값입니다.")
}
score의 70이라는 값이 case 70:에 해당되어 "70입니다"문장이 출력되었다.
var a = 10
switch a {
case 88:
print("88")
case 10,20,30: //다중 값을 적을 수 있다. 하나라도 해당되면 구문을 실행한다.
print("10,20,30입니다.")
case 70...80: //70이상 80이하 범위 값
print("70...80입니다.")
case 50..<60: //50이상 60미만 범위 값
print("50..<60입니다.")
case 200...: //200이상
print("200...입니다.")
case ...150: //150 이하
print("...150입니다.")
case ..<170: //170미만
print("..<170입니다.")
default:
print("기본값입니다.")
}
스위프트의 switch문은 또 다른 차별점이 있는데, 바로 case문에 다중 값, 범위, 조건절 등 을 추가할 수 있다는 것이다.
let score = 85
let color = "red"
switch color{
case "red" where score % 2 == 0: //score가 짝수이면서, color가 red인 경우
print("red 짝수")
case "red" where score >= 80: //score가 80이상이면서, color가 red인 경우
print("red 우수")
case "blue":
print("blue")
case "green":
print("green")
case "red" where score >= 60: //score가 60이상이면서, color가 red인 경우
print("red 정상")
case "red":
print("red")
default:
print("default")
}
스위프트의 switch에는 where절을 통해 조건을 걸수 있는 것이 큰 특징이다. 단, switch문을 사용할 때 알아 두어야 할 점은 대상이 두 개 이상의 case에 부합하더라도, 먼저 적힌 case의 실행구문만 실행 된다는 점이다.
연산자(operator)는 항을 재료로 계산 후 결과를 반환해주는 것이다. 연산자에 의해 연산되는 값의 수에 따라 단항, 이항, 삼항 등으로 구분하기도 하며, 연산자의 위치에 따라 전위, 중위, 후위 등으로 구분하기도 하는데, 그 중에서도 오늘은 이항연산자와 삼항 연산자에 대해 알아보도록 한다.
산술 연산자
이항 연산자의 한 종류이다. 덧셈, 뺄셈, 곱셈, 나눗셈, 나머지 계산이 가능하다.
var a = 20, b = 3
print("a+b: \(a+b)")
print("a-b: \(a-b)")
print("a*b: \(a*b)")
print("a/b: \(a/b)")
print("a%b: \(a%b)")
문자열에는 덧셈연산이 결합연산으로 적용된다.
var x = "맛있는"
var y:String = "피자"
print("x: \(x)")
print("y: \(y)")
print("x+y: \(x+y)")
한가지 주의해야 할 점은 스위프트의 연산자는 다른 언어와 달리 같은 자료형이어야만 동작한다는 점이다. 따라서 다른 자료형끼리 연산을 할 때에는 자료형 변환을 통해서 자료형을 맞추어 주어야 한다. 산술연산에는 당연히 계산 우선순위가 존재한다.
비교 연산자
Bool을 반환하는 이항연산자이다. 초과, 미만, 이상, 이하, 같다, 다르다를 비교하여 결과값으로 bool형을 반환한다.
a=10; b=20
print(a , ">", b, ":", a > b)
print(a , "<", b, ":", a < b)
print(a , ">=", b, ":", a >= b)
print(a , "<=", b, ":", a <= b)
print(a , "==", b, ":", a == b)
print(a , "!=", b, ":", a != b)
문자열의 비교도 가능하다. 가나다 순으로 비교를 하며 후위의 글자가 더 높은 것으로 판단한다. 앞글자가 같다면 글자수가 더 많은 글자가 더 높은 것으로 판단한다.
x = "정우성" ; y = "정좌성"
print(x , "<", y, ":", x < y)
print(x , ">", y, ":", x > y)
print(x , "<=", y, ":", x <= y)
print(x , ">=", y, ":", x >= y)
print(x , "==", y, ":", x == y)
print(x , "!=", y, ":", x != y)
var height = 195.4
var color = "grey"
print("height >= 185+20 && color == \"red\" : ", height >= 185+20 && color == "red")
print("height >= 185-10 || color == \"red\" : ", height >= 185-10 || color == "red")
산술 > 비교 > 논리 순서로 연산이 이루어진다.
복합할당 연산자
할당(대입)연산과 다른 연산을 한번에 할 수 있도록 결합되어진 연산자다.
a = 8
print("a:", a)
a += 3
print("a += 3:", a )
a -= 3
print("a -= 3:", a )
a *= 3
print("a *= 3:", a )
a /= 3
print("a /= 3:", a )
a %= 3
print("a %= 3:", a )
삼항 연산자
조건식 ? A : B
항이 3개이다. 조건식이 참이라면 A를 반환, 거짓이라면 B를 반환한다.
var score = 85
var res = score >= 80 ? "합격" : "불합격"
print(score,":",res)
score가 80이상이라는 조건식을 만족하였으므로 "합격"이 res변수에 대입된 것이다.
casting
형 변환(casting)이란, 서로 다른 자료형과의 연산을 위해, 혹은 변수를 다른 형태로 표현하기 위해 자료형을 변환하는 것을 뜻한다. 보통 자료형(변수) 형태로 사용한다.
var x = 30
var y = 1.2
var z = x + y //Binary operator '+' cannot be applied to operands of type 'Int' and 'Double'
서로 다른 자료형은 연산을 할 수 없다는 에러가 표시된다.
var x = 30
var y = 1.2
var z = Double(x) + y
print("z:",z)
예시와 같이 변수 x를 형변환을 통해 실수형으로 변환하여 두 변수의 연산이 가능해진다.
그렇다면 형변환을 하게 되면 자료는 어떤 식으로 변화가 일어날까?
var x = 30
var y = 1.8
print("Double(x):",Double(x))
print("Int(y):",Int(y))
정수형을 실수형으로 변환 시 큰 문제가 없다. 소수점 .0이 추가될 뿐이다. 하지만 실수형을 정수형으로 변환 시 소수점 이하 자리는 없어지게 된다. 따라서 자료형 변환 시 손실되는 자료가 생기는지 확인이 필요하다.
var h:Int16 = 128
print(Int8(h))
위와 같은 경우도 조심해야 한다. Int16에서는 128을 표현할 수 있지만, Int8의 범위는 127 ~ -128 즉 128은 Int8에는 담을 수 없는 표현 범위의 숫자이다. 형 변환을 시도할 때에는 이러한 여러가지 문제점이 발생 할 수 있다는 점을 알아두자.