클래스의 특성에는 initializer(생성자), self, inheritance(상속)가 있다.
init( )
클래스는 객체생성 시 자동으로 단 한번만 생성자 메소드를 호출한다. 스위프트에서는 init()이라는 이름으로 사용한다.
주로 클래스 멤버변수 초기화의 용도로 사용을 한다.
class AAA{
var a = 10
var b = "아기상어"
init(aa:Int, bb:String){s
//생성자 --> 멤버변수 초기화로 주로 사용한다.
print("AAA initializer start: \(aa), \(bb)")
a = aa
b = bb
}
func fn_1(){
print("AAA fn_1() start: \(a), \(b)")
}
func fn_2(){
print("AAA fn_2() start: ")
}
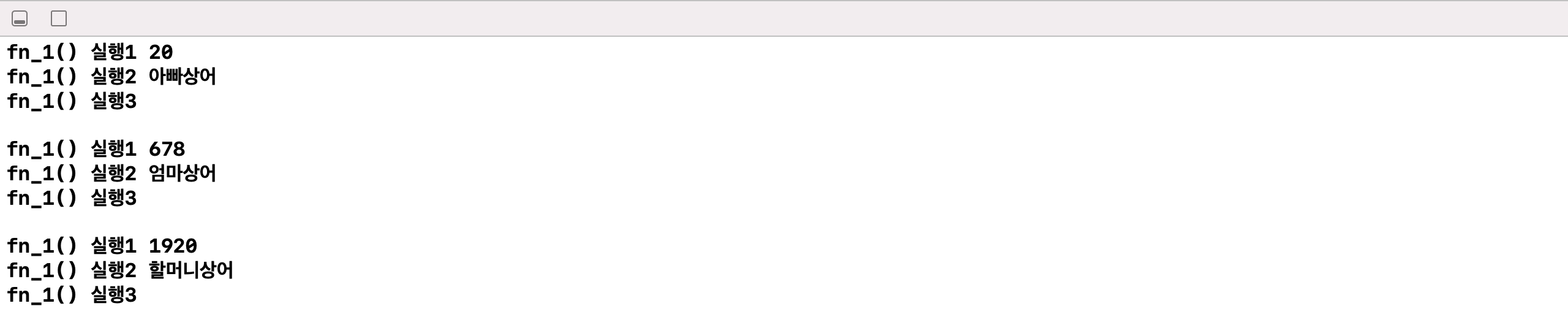
}var cc1 = AAA(aa:1234, bb:"엄마상어")
var cc2 = AAA(aa:456, bb: "할아버지상어")
cc1.fn_1()
cc2.fn_1()
init()은 따로 호출하지 않아도 알아서 실행이 되는 모습을 볼 수 있다. 예시와 같이 생성자를 통해 객체 생성과 동시에 변수의 초기화가 이루어지니 더 간결하게 코드를 적을 수 있다.
var arr = [AAA(aa:10, bb:"정우성"),
AAA(aa:20, bb:"정좌성"),
AAA(aa:60, bb:"정남성"),
AAA(aa:80, bb:"정중성")]
for qq in arr{
qq.fn_1() //배열로 담아 메소드 실행
}
배열을 이용하여 메소드를 실행할 수 있다는 점도 알아두자.
self
self는 멤버요소 접근자로서 자기 자신 클래스 내 멤버변수에 접근할 때 사용된다.
class AAA{
var a:Int!
var b:String!
init(_ a:Int, _ b:String){
self.a = a //self -> 현재 인스턴스의 멤버요소 접근자.
self.b = b //매개변수와 멤버변수의 혼동을 막기위해 명시적으로 선언하기 위한 용도로도 쓰인다.
ppp()
}
func ppp(){
print("a:\(a!), b:\(b!)")
}
}var zx = AAA(123, "조인성") //한번만 사용할 것이라면, 굳이 변수로 담지 않아도 된다.
위 예제는 init()의 매개변수와 클래스내의 멤버변수가 이름이 같아 혼동이 될수 있기에 명시적인 목적으로 사용했다.
self 예제 1
각 선분의 길이를 입력받으면 어떤 도형인지, 도형의 넓이, 도형의 둘레를 측정하는 클래스를 작성해보았다. 편의상 사각형은 직각사각형, 삼각형은 직각삼각형으로 취급했다.
class Shape{
var name:String!
var line:[Int]!
var area = 0, border = 0
init(_ line:Int...){ //사용자 정의 생성자 -- 필요한 멤버요소 획득
self.line = line
name = ["원","직사각형","직각삼각형"][line.count-1] //line.count-1은 인덱스를 담당하게된다.
calc() //연산
}
func calc(){
if name == "원"{
let pi = 3.14
self.area = Int(Double(self.line[0]) * Double(self.line[0]) * pi)
self.border = Int(Double(self.line[0]) * 2.0 * pi)
} else if name == "직사각형"{
area = line[0] * line[1]
border = (line[0] + line[1]) * 2
} else if name == "직각삼각형"{
area = line[0] * line[1] / 2
border = line[0] + line[1] + line[2]
}
}
func ppp(){
print("\(name!): \(area), \(border)")
}
}var shapes = [
Shape(5),
Shape(5,6),
Shape(5,6,8),
Shape(10,20),
Shape(14,16,21),
Shape(8)
]
for sh in shapes{
sh.ppp()
}
self 예제 2
학생클래스를 정의하고 학생 정보를 출력해보았다.
클래스명: Stud
입력내용: 이름,국어,영어,수학
출력정보: 이름,국어,영어,수학,총점,평균
class Stud{
var name:String
var kor:Int
var eng:Int
var math:Int
var tot = 0
var avg = 0
init(_ name:String, _ scores:Int...){
self.name = name
self.kor = scores[0]
self.eng = scores[1]
self.math = scores[2]
calc()
}
func calc(){
tot = kor + eng + math
avg = tot/3
}
func ppp(){
print("name:\(name)\t국어:\(kor)\t영어:\(eng)\t수학:\(math)\t총점:\(tot)\t평균:\(avg)")
}
}var studs = [Stud("라이언",86,87,89),
Stud("어피치",77,76,74),
Stud("프로도",65,66,68),
Stud("제이지",99,97,95)
]
for st in studs{
st.ppp()
}
Inheritance
Inheritance(상속)는 상위클래스의 요소를 자식클래스가 가져와 사용할 수 있는 객체지향언어의 가장 큰 특징이다.
상속의 선언은 다음과 같다.
class 자식클래스 : 부모클래스 {
실행코드 ...
}
자식클래스는 부모클래스의 멤버변수와 메소드를 사용할 수 있는데, 메소드는 자식클래스의 필요에 따라 overriding(재정의)이 가능하다. 상속을 이용하는 가장 큰 이유이며 이렇게 하나의 메소드가 호출하는 주체에 따라 다르게 동작하는 것을 polimolphism(다형성)이라고 한다.
class Par{
var a = 10
var b = "부모"
func fn_1(){
print("부모 fn_1()")
}
func fn_2(){
print("부모 fn_2()")
}
}
class Child : Par{ //상속관계 정의(자식 : 부모)
var c = 3000
override func fn_2(){ //overriding 재정의. 부모의 메소드를 재정의하여 사용한다.
print("자식 fn_2()")
}
func fn_3(){
print("자식 fn_3()")
}
}
class Child2 : Par{ //상속관계 정의(자식 : 부모)
var d = 4040
func fn_4(){
print("자식2 fn_4()")
}
}var pp = Par()
var cc = Child()
var cc2 = Child2()
print("pp-----------")
print(pp.a,pp.b)
pp.fn_1()
pp.fn_2()
print("cc-----------")
print(cc.c)
print(cc.a,cc.b,cc.c)
cc.fn_3()
cc.fn_1()
cc.fn_2()
print("cc2-----------")
print(cc2.d)
//print(cc2.c) //Child클래스의 멤버변수에 접근 불가.
print(cc2.a,cc2.b,cc2.d)
//cc2.fn_3() //Child클래스의 메소드에 접근 불가.
cc2.fn_4()
cc2.fn_1()
cc2.fn_2()

예제를 보면 알 수 있듯이 자식 클래스들은 모두 부모 클래스에 접근이 가능하지만, 서로 다른 자식클래스들은 서로 간에 접근이 불가능하다. 또한 같은 함수를 호출하더라도 overriding이 되어있는지의 여부에 따라 다른 결과물이 출력되는 점도 확인 할 수 있다.
객체지향언어의 꽃이라고 볼 수 있는 상속은 누군가 체계적으로 작성한 클래스를 상속, 재정의하여 본인에게 알맞게 사용 가능하다는 점이 매력적인 기능이다.
'iOS > TJ' 카테고리의 다른 글
| day12_funcVariable, selfCall, class (0) | 2021.06.29 |
|---|---|
| day11_param, return, funcCall (0) | 2021.06.18 |
| day10_func() (0) | 2021.06.17 |
| day09_dictionary, set (0) | 2021.06.16 |
| day08_multiArray, tuple (0) | 2021.06.03 |